
곰
파이썬 데이터 전처리 본문
데이터 인코딩
레이블 인코딩(Label encoding)
from sklearn.preprocessing import LabelEncoder
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# LabelEncoder 클래스를 encoder 객체로 생성한 후
encoder = LabelEncoder()
# fit은 transform 수행 전 틀을 맞춰주는 역할
encoder.fit(items)
# encoder.transform( ) 으로 label 인코딩 수행.
labels = encoder.transform(items)
print('인코딩 변환값:', labels)인코딩 변환값: [0 1 4 5 3 3 2 2]
print('인코딩 클래스:', encoder.classes_)인코딩 클래스: ['TV' '냉장고' '믹서' '선풍기' '전자렌지' '컴퓨터']
print('디코딩 원본 값:', encoder.inverse_transform([0, 1, 4, 5, 3, 3, 2, 2]))디코딩 원본 값: ['TV' '냉장고' '전자렌지' '컴퓨터' '선풍기' '선풍기' '믹서' '믹서']
원-핫 인코딩(One-Hot encoding)
sklearn에서의 원핫 인코딩
<sklearn에서의 원핫 인코딩은 좀 복잡하다>
첫번째, 먼저 숫자값으로 변환을 위해 LabelEncoder로 변환합니다.
두번째, 2차원 데이터로 변환합니다. (reshape 활용)
마지막으로 원-핫 인코딩을 적용합니다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items=['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서']
# 첫번째, 먼저 숫자값으로 변환을 위해 LabelEncoder로 변환합니다.
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
labelsarray([0, 1, 4, 5, 3, 3, 2, 2], dtype=int64)
# 두번째, 2차원 데이터로 변환합니다.
labels = labels.reshape(-1, 1)
labelsarray([[0],
[1],
[4],
[5],
[3],
[3],
[2],
[2]], dtype=int64)
# 마지막으로 원-핫 인코딩을 적용합니다.
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels) # fit -> transform 항상 fit 이후에는 transform
oh_labels = oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.shape)
oh_labels.toarray()원-핫 인코딩 데이터 (8, 6)
Out[8]:
array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.]])
판다스의 원핫 인코딩
판다스의 get_dummies 함수를 이용하면 쉽게 원핫 인코딩이 가능하다
import pandas as pd
df = pd.DataFrame({'item':['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서'] })
df
pd.get_dummies(df)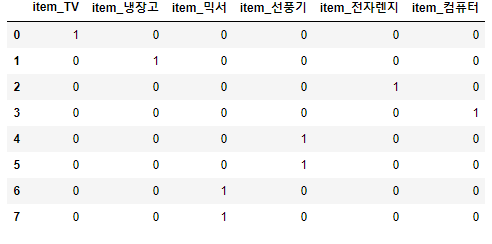
피처 스케일링과 정규화
StandardScaler
from sklearn.datasets import load_iris
import pandas as pd
# 붓꽃 데이터 셋을 로딩하고 DataFrame으로 변환합니다.
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df.mean())
print('\nfeature 들의 분산 값')
print(iris_df.var())feature 들의 평균 값
sepal length (cm) 5.843333
sepal width (cm) 3.057333
petal length (cm) 3.758000
petal width (cm) 1.199333
dtype: float64
feature 들의 분산 값
sepal length (cm) 0.685694
sepal width (cm) 0.189979
petal length (cm) 3.116278
petal width (cm) 0.581006
dtype: float64
from sklearn.preprocessing import StandardScaler
# StandardScaler객체 생성
scaler = StandardScaler()
# StandardScaler 로 데이터 셋 변환. fit( ) 과 transform( ) 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_scaled
# transform( )시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
pd.DataFrame(iris_df_scaled)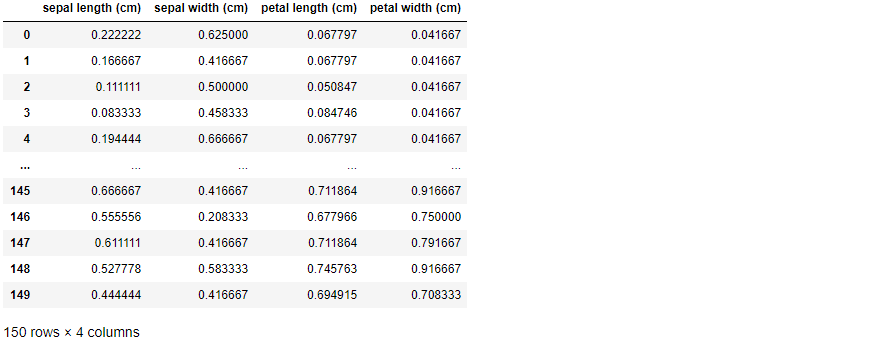
print('feature 들의 평균 값')
print(iris_df_scaled.mean())
print('\nfeature 들의 분산 값')
print(iris_df_scaled.var())feature 들의 평균 값
sepal length (cm) -1.690315e-15
sepal width (cm) -1.842970e-15
petal length (cm) -1.698641e-15
petal width (cm) -1.409243e-15
dtype: float64
feature 들의 분산 값
sepal length (cm) 1.006711
sepal width (cm) 1.006711
petal length (cm) 1.006711
petal width (cm) 1.006711
dtype: float64
MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler객체 생성
scaler = MinMaxScaler()
# MinMaxScaler 로 데이터 셋 변환. fit() 과 transform() 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df) # transform()시 scale 변환된 데이터 셋이 numpy ndarry로 반환되어 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('feature들의 최소 값')
print(iris_df_scaled.min())
print('\nfeature들의 최대 값')
print(iris_df_scaled.max())feature들의 최소 값
sepal length (cm) 0.0
sepal width (cm) 0.0
petal length (cm) 0.0
petal width (cm) 0.0
dtype: float64
feature들의 최대 값
sepal length (cm) 1.0
sepal width (cm) 1.0
petal length (cm) 1.0
petal width (cm) 1.0
dtype: float64
pd.DataFrame(iris_df_scaled)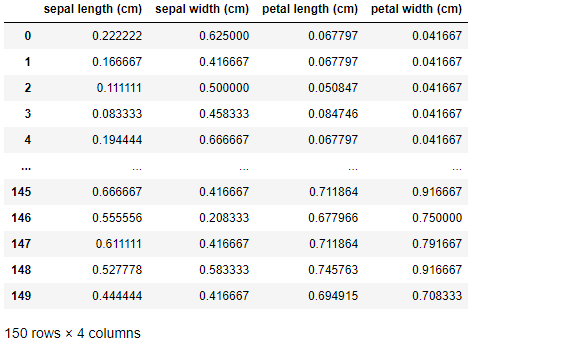
'파이썬 머신러닝' 카테고리의 다른 글
| ROC AUC 예제 (1) | 2021.05.21 |
|---|---|
| 사이킷런 타이타닉생존자 예측 (0) | 2021.05.20 |
| sklearn.model_selection(train_test_split, 교차검증) (0) | 2021.05.06 |
| 사이킷런의 내장 예제 데이터 (0) | 2021.05.06 |
| 사이킷런을 이용한 붓꽃 데이터 품종 예측하기 (0) | 2021.05.06 |



